This document contains all the information necessary to understand the application and its implementation. It explains the design decisions and how the different components interact with one another and with other systems.
After reading this document, you will gain a good understanding of how the application operates.
This section contains a brief description of how the application works, its parts and how they interact with each other.
Kive is a kubernetes-native eBPF-powered file access monitoring tool. The user is able to select which file to monitor based on the path and filters on pods / containers. When one of the monitored files is accessed (read from, written to..), the application will inform the user by generating an alert.
processes that access the file
/etc/shadow on all containers in pods that have the
security=high label.The application is implemented as a single kubernetes operator and is structured into multiple components that interact with each other, kubernetes or the operating systems.
The components are:
KivePolicy resource.KiveAlerts and
manages the KiveData resource.A detailed description of the aforementioned components is given later in this document.
eBPF programs are programs that run inside the kernel in a controlled environment. There are varous types of eBPF programs, which are executed in different contexes and moments, for example some program types can be hooked to existing tracing infrastructure such as tracepoints, perf events and kprobes, and they will be executed when the hook is triggered. An eBPF program uses its own instruction set and the kernel will either interpret it (less common) or JIT compile it to native machine code after a verification step where several contraints are asserted. For example, eBPF program can have at most 512 Bytes of stack size and 1 million instruction, unbounded loops are not allowed and only certain functions (helpers or kfunctions) can be called. Note that those (and many other) limitations are changing rapidly and the kernel verifier is getting always smarter, allowing for softer limits.
Usually you do not write bytecode directly; instead you let a compiler generate it for you. Traditionally, BCC is used to compile said programs, however, both LLVM and GCC have caught up and now provide an eBPF target.
To enable loading compiled eBPF programs on different versions of the
linux kernel, Bpf Type Format (BTF) was introduced, providing CO-RE
(Compile Once, Run Everywhere) compilation. User space provides eBPF
programs to the kernel via the bpf(2) syscall, which will
verify that the program is correct (enforcing the limitations) and will
proceed to JIT compile it to native instructions.
eBPF is particularly useful for monitoring and tracig uses cases, and recently it has been used to extend the kernel in more meaningful ways such as customized scheduling or memory management.
Kubernetes is a declarative container management software. The user specifies the desired state of the cluster and kubernetes will try to update the current state to the desired state. Applications should expect to be interrupted at any time and failures should be handled gracefully. Kubernetes can work with multiple container runtimes such as containerd or podman, and interacts with the containers through their runtime (for example, via a containerd client). Therefore, kubernetes abstracts the management of single container, and focuses on the scheduling and setting up of containers in a physical or logical cluster.
Each unit on the cluster is called a node. There are two kinds of nodes: a worker node and the control plane. The former will run applications and services through contianers grouped in pods, the latter forms the backbone of the kubernetes cluster and is responsible for central management of the workers. The most important components are the api server (which the kubelet use to communicate with the control pane) etcd (a highly-available key-value store), scheduler and a controller manager which manages all of the above.
A common pattern found in kubernetes is the Operator, which is a custom controller that manages some custom resources hereby extending the behavior of the cluster. Note that the same operator may have multiple controllers for different custom resources, as we will see later.
Briefly, the end goal is to log when a file is accessed, that is, when an actor interacts with It by opening, closing, writing, appending and so on.
The application uses eBPF programs to monitor accesses. More specifically, the eBPF program gets executed when a certain kernel function is called through a kprobe, and It will check if said function interacts with any of the files specified by the user. If that is the case, It should log the information with additional metadata such as which PID called the function. The choice of what function to hook to is crucial for the correct behaviour of the application.
The information of which files to check is provided from userspace to the eBPF program via a map, which is a shared array between userspace and kernelspace (can be read from and written to in both cases).
You can think of eBPF programs as simple programs that run inside the kernel with some limitations to ensure certain safety measures. They can access some internal kernel structures that would only be available through kernel modules which are more powerful and, therefore, dangerous.
The eBPF program needs to be loaded and updated when the user changes
the monitoring policy (KivePolicy) or the cluster changes /
updates its topology. Therefore a loader and an updater are necessary,
which are both done by the loader controller, as well as
capturing information from the eBPF program and generating alerts
(KiveAlert). A more satisfying description will be given
later.
To identify a particular file, we can use its path name. There cannot be two different files with the same path name, however you can create a symlink to a file: the path of the symlink will be different from the path of the original file but the actual data will be the same.
To circumvent this, we are using the inode number instead. Each file has an inode number that is unique in the filesystem that he lives in. This is how the kernel internally identifies data.
However, there is still an edge case where different filesystems may have different files with the same inode number. This happens because the inode number is an identifier in a filesystem, but It has no meaning on another filesystem and may aswell point to a different file.
To solve this problem, we can use both the inode number and the device id as unique identifiers. Even if a filesystem is binded onto another, the binded filesystem and the filesystem onto which the binded one is mounted have different inode numbers so the key remains unique.
In our application, the entity that is responsible to get the inode
number is the discover controller. The loader controller and
the discover controller share information through a
KiveData resource.
Now, imagine all that we have just said, but inside containers in a very dynamic environment where things may change and break at any time. There may be multiple operating systems on the same cluster so we need to load one eBPF program for each one of them, but not more than one on the same kernel to save resources. We need to access inode numbers of files inside containers, pods can be scheduled in any node, and so on. All of this needs to be handled carefully, increasing the complexity of the design.
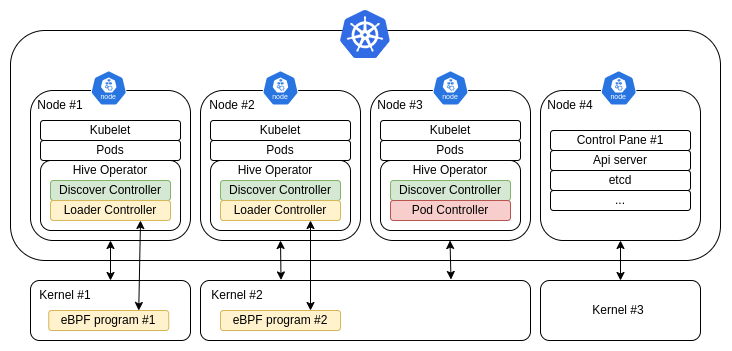
An example deployment would look like the following:
On the picture, notice that Kernel #2 only has one loader. Each kernel has only one loader, which is chosen through leader elections. Instead, the discover controller is active in each node because It has to find information about other pods that may be scheduled in any node. There is only one pod controller on the entire cluster. The control plane usually does not run pods, but it can be configured It to do like a normal node; if this is the case, the operator will be scheduled to this node too.
This section describes the application in more depth. It is recommended to read the overview section first in order to get a general understanding of the application before reading the details.
The design of this application was conducted considering the following:
The different components are now described below:
The discover controller aka KivePolicy
controller is responsible for the following:
Identify the kernel instance: the controller will fetch an unique
identifier for the running kernel (for example reading
/proc/sys/kernel/random/boot_id).
This is needed because the loader should send to the eBPF program only the inodes that exist on the running kernel. In other words, and inode makes sense only in the kernel where It runs. Therefore, the discover controller needs to identify its running kernel in order to share the inodes with the right loader (there is one loader per running kernel, more info below).
reacting to CRUD operations on KivePolicy resource,
which will:
KiveData resources with the previously fetched
informationThe KiveData resource is specified later in KiveData resource.
Note that when referring to inodes in this document we are technically referring to the inode number.
There must be one discover controller for each node. This is necessary because the controller has to interface directly to the container runtime and access the filesystem of the container in order to read the inode.
Therefore, each discover controller instance will react to all the
changes in the KivePolicy resource, and generate one or
multiple KiveData resource[s] for this specific kernel.
Any discover controller[s] may generate multiple
KiveData resources from the same KivePolicy.
This is intended by design since the policy may match multiple pods
hence the relationship between a policy and a KiveData is
one to many.
A KivePolicy resource contains a list of
KiveTrap, and looks like this:
apiVersion: kivebpf.san7o.github.io/v1
kind: KivePolicy
metadata:
labels:
app.kubernetes.io/name: kivebpf
name: kive-sample-policy
namespace: kivebpf-system
spec:
alertVersion: v1
traps:
- path: /secret.txt
create: true
mode: 444
callback: "http://my-callback.com/alerts"
matchAny:
- pod: nginx-pod
namespace: default
ip: 192.168.0.3
containerName: "regex: .*"
matchLabels:
security-level: high
metadata:
severity: criticalEach KiveTrap can contain the following fields:
This field specifies which version of the HiveAlert to
output. By default, this is set to the lastest stable API.
This is the only non-optional fiels. path is the
filesystem path in a matched container starting from the root
/ directory of the file to trace.
The user may decide to create the file if not present by specifying
create: true in the policy. Furthermore, the user can
specify the UNIX permissions given to the file to be created via the
mode field.
If present, the operator will send json-encoded data to the callback via an HTTP POST request.
Optional additional information regarding the trap. It is a list of
key value pairs. The metadata will be reported in the
KiveAlert under the custom-metadata item.
The matchAny field contains a list of match blocks which
will be matched with a logical OR. Each match block contains one or more
match items matched with a logical AND, which include:
pod: the name of the podnamespace: the namespace of the podcontainer-name: the name of the container, or a patter
to match the name. There are three possible cases:
regex:, the rest of the
string will represent a regular expressionglob:, then this is a
filesystem-style regex, as described in go
filepath.Match.ip: the ipv4 of the podmatchLabels: a list of labels and valuesAt least one match block with one match item must be present.
Examples:
matchAny:
- pod: nginx-pod
namespace: defaultThe above selects all the containers in pods with name
nginx-pod AND those that are in the default
namespace.
matchAny:
- pod: nginx-pod
- namespace: defaultThe above matches all containers that are in pods named
nginx-pod OR all the containers that are in the
default namespace.
The controller performs the following actions in sequence when a CRUD
operation occurs on an KivePolicy resource (a
“reconciliation”):
Identify the kernel instance: the controller will fetch an unique
identifier for the running kernel (for example reading
/proc/sys/kernel/random/boot_id).
This is needed because the loader should send to the eBPF program only the inodes that exist on the running kernel. In other words, and inode makes sense only in the kernel where It runs. Therefore, the discover controller needs to identify its running kernel in order to share the inodes with the right loader (there is one loader per running kernel, more info below).
This is node only once at startup.
Initialize a connection with the container runtime of the kubelet where the controller lives, if not previously done. Interfacing to the container runtime is necessary to know which PID corresponds to which container, and through the PID we can access the filesystem.
Read all the KivePolicies and their respective
KiveTraps.
If an KivePolicty is about to be deleted (using
finalizers), trigger a reconciliation for KiveData, which
will be responsible for deleting any resource that does not belong
anymore to a KiveTrap.
For each trap, get the list of matched containers, then check if
a KiveData resource already exists for each of them.
If it does not exist:
Read the inode of the file specified by the trap.
Create the KiveData with the information from the
container, the pod, the trap, the policy, and the inode.
Compute an identifier of the policy and set it as a label in the
KiveData.
If either the container or pod are not ready, requeue and restart from point 2.
To summarize, if an KivePolicy is created / updated, the
reconciliation will check if a KiveData was already
present, or create it otherwise. If an KivePolicy is
deleted, we delegate the responsibility of deleting old
KiveData to the KiveData reconciliation.
The loader controller aka KiveData controller is
responsible for the following operations:
KiveData resource.KiveAlerts: the controller will read the
output of the eBPF program from a ring buffer, parse it, add kubernetes
information (such as the name of the pod corresponding to the inode and
other information from the kubernetes topology) and generate an
KiveAlert, which will either be printed to standard output
or sent to a callback via a POST HTTP request.Upon rescheduling of the operator, the eBPF program needs to be reloaded (closed and loaded again).
There must be one loader controller for each running kernel. This is necessary because the loader interacts directly with the running kernel. It is useless to have multiple loaders in the same kernel, but at least one is necessary to load the eBPF program.
To implement this, each node needs to fetch its running kernel identifier and then run elections so that only one node is elected per running kernel.
The KiveData resource is used to communicate information
between the discover and the loader controller. The relationship between
an KiveTrap and an KiveData is one to many,
where each KiveData must have an KiveTrap.
The loader uses information from this resource to instruct the eBPF program to filter certain inodes.
The schema of the resource looks like the following:
apiVersion: kivebpf.san7o.github.io/v1
kind: KiveData
metadata:
annotations:
kive-alert-version: v1
kive-policy-name: kive-sample-policy
callback: ""
container-id: containerd://da9e46ae1873ec463c9dafd08d2be762867e92b740b5c5b4534c6ad0c270d1e5
container-name: nginx
namespace: default
node_name: kive-worker2
path: /secret.txt
pod_ip: 10.244.1.2
pod_name: nginx-pod
creationTimestamp: "2025-07-25T08:06:12Z"
generation: 1
name: kive-data-nginx-pod-default-13667586
namespace: kivebpf-system
resourceVersion: "23395"
uid: 788bcb67-a9de-480d-a179-e40234116459
labels:
trap-id: c4705ec263cc353100b6f18a129e32b67b79171bcb0c90b2731a7923ea4dcee
kernel-id: fc9a30d5-6140-4dd1-b8ef-c638f19ebd71
spec:
inode-no: 13667586
dev-id: 3
metadata:
severity: criticalThe fields under spec are:
inode-no: The inode number of the file to monitor,
needed by the eBPF program.dev-id: The device id associated with the file to
monitor.metadata: Additional information to report in the
alert.The annotations are used as additional information for the
KiveAlert when an access is detected by the eBPF
program.
The trap-id label is used to identify which
KiveTrap generated this KiveData. The label
kernel-id is an unique identifier of a running kernel, to
discriminate which loader controller should handle this
KiveData.
Upon CRUD changes of the KiveData resource, the
controller does the following:
Fetch the KivePolicy and KiveData
resources in the cluster.
Check if each KiveData (referring to this kernel id)
does have a corresponding KiveTrap from an
KivePolicy.
If it does, then we update the eBPF map with the information from the
KiveData. It it does not, then the KiveTrap
has been eliminated and the KiveData should be deleted.
To check whether an actor has interacted with a file, the eBPF
program hooks to the function inode_permission through a
keyprobe. This function gets called every time the permissions of an
inode are checked in the kernel, which appends before any operation on
them. It allows the eBPF program to log when a permission is checked and
with what rights, as well as who tried to check the permissions.
The eBPF program will log information only if said function is called
on an inode present in an KiveData resource. The loader
will fetch those inodes from the CRD and send them to the eBPF program
via a map, that is an array of inodes.
The info is sent in a kernel ringbuffer accessible by the operator for logging purposes.
The eBPF program uses BTF types information to enable compile-once run everywhere (CORE) meaning that the ebpf program does not need to be compiled each time It needs to be loaded, but can be compiled only once and even shipped with the binaries of the application.
The information from the ring buffer will be processed by the loader
to generate an KiveAlert. An example alert is the
following:
{
"kive-aler-version": "v1",
"kive-policy-name": "kive-sample-policy",
"timestamp": "2025-08-02T16:51:19Z",
"metadata": {
"path": "/secret.txt",
"inode": 16256084,
"mask": 36,
"kernel-id": "2c147a95-23e5-4f99-a2de-67d5e9fdb502"
},
"custom-metadata": {
"severity": "critical",
},
"pod": {
"name": "nginx-pod",
"namespace": "default",
"container": {
"id": "containerd://0c37512624823392d71e99a12011148db30ba7ea2a74fc7ff8bd5f85bc7b499c",
"name": "nginx"
}
},
"node": {
"name": "kive-worker"
},
"process": {
"pid": 176928,
"tgid": 176928,
"uid": 0,
"gid": 0,
"binary": "/usr/bin/cat",
"cwd": "/",
"arguments": "/secret.txt -"
}
}When a pod is changed, we want to update both KiveData
and the eBPF map. To achieve, this we need a pod controller. There are
two main operations we are concerned about with pods: pod creation and
pod termination. - creation: upon creation, the controller should send a
reconcile request for KivePolicy so that new
KiveData will be generated for the new pod. - termination:
upon termination, the controller should check if each
KiveData refers to an existing pod. If it does not, then
that resource should be eliminated.
Failures are treated as terminations.
The implementation of said logic is achieved through a reconcile function like other controllers.
Since Pods are global resources accessed from anywhere, we need only one pod controller in the cluster. This is the sole reason why we need a separate controller from the others: there is a discover controller on each system, a loader controller on each running kernel, and a single pod controller per cluster.